世にスマートスピーカーが普及して数年がたち、「機器」とのインターフェースに人の言葉を利用することが増えています。株式会社コトバデザイン様は、この「言葉」によるインターフェースの可能性をさらに押し広げ、様々なシステムやサービスを誰もが自然に利用できるように、あらゆる所に対話エージェントがインターフェースとして実装され、活用される世界の実現を目指しているスタートアップです。同社が目指す世界や取組について、取締役 CTOの土田様とプリンシパルリサーチャーの松田様にお話を伺いました。

株式会社 コトバデザイン
取締役 CTO 土田 正明 様(前列右端)
プリンシパルリサーチャー 松田 繁樹 様(後列真中)
― 先ずは御社のプロフィールを簡単に教えていただけますか?
土田 正明 (以下、土田):
はい、当社は2017年8月に創業した株式会社コトバデザインといいまして、対話エージェントの開発・販売、またそういう対話エージェントを流通させていくための仕組み作りを目指している企業になります。
― 対話エージェントという意味では、既に我われの身近にはスマートスピーカーなどもありますが、この事業を始められたきっかけは何だったのでしょう?
土田:
はい、私自身は2018年4月入社なので本当の創業時からのメンバーというわけではないのですが、今ある対話エージェントは、本来持つポテンシャルからしたらまだまだ限定的で、誰もがシステムやサービスを自然に使うためのインターフェースとして、今後ますます重要になると考えて創業したと理解しています。
今のスマートスピーカーをはじめとした対話インターフェースって、基本的には「こういうことをして」って言ったら、機能を呼び出すような音声コマンドみたいな感じですよね。もちろんそれらも便利で素晴らしいのですが、これは使い慣れた機能の呼び出しのショートカットのようなもので、誰もが自然に使えるインターフェースという方向とはまた違うかなと思っています。
― なるほど、御社の理想とする対話エージェントとはちょっと違うということですね?
土田:
ええ、イメージとしては対話エージェントがもっと人間により添っているような感じですね。例えば、状況をウォッチしながら話しかけてくれる、こっちが呼び出したら答えてくれるというよりも「助けましょうか?」とか「こういうことですか?」とか「こうしてみたらどうですか?」っていう感じです。ずっと同じ対話エージェントを使っていくことで使用者が「自分のことを理解してくれている」という感覚も重要になるだろうと考えています。
究極的にはあらゆるシステムとか機器に対して、そのような対話インターフェースが当たり前のように実装されているようにしたいと考えています。
― 御社の事業説明に「対話AIのコンテンツ化と流通」とありました。AIの「コンテンツ化」とはどういうことでしょうか?
土田:
たぶん少し違和感のある表現ですよね。じゃあちょっと説明しますね。
先ず前提なのですが、対話エージェントでは、一個のすごいモデルであらゆる状況に対応するみたいなことはできないと考えています。未来にはできるかもしれないですが、現状で商用の実装を考えたときには全く現実的ではないと思っていて、今は用途をしぼって、それに合わせてそれぞれの対話システムを作っていくことになるんですね。
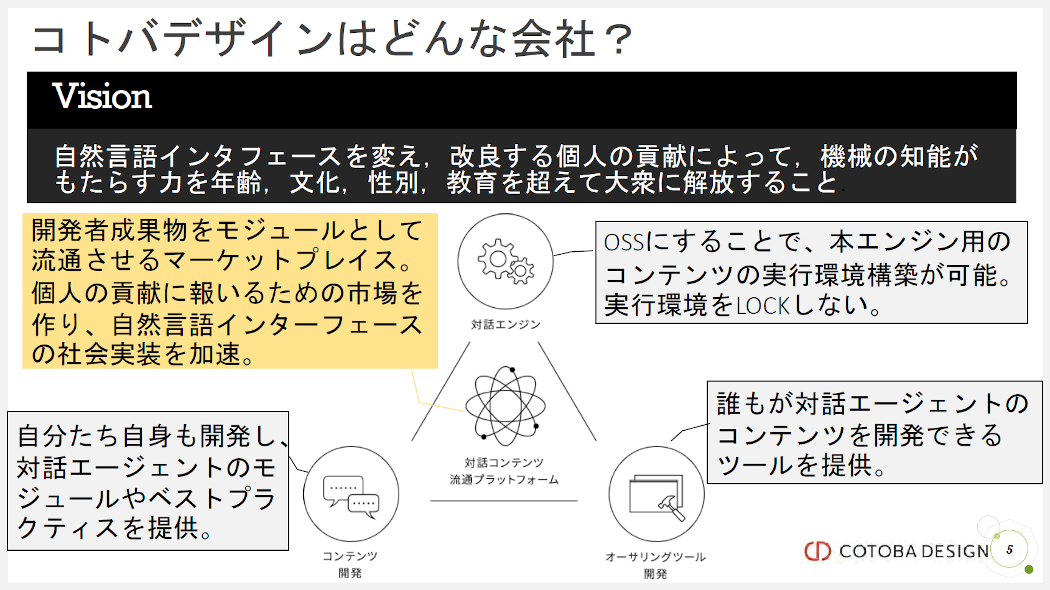
それで、対話システムも基本的には「ソフトウェア」だと思うんですけど、それを対話のエンジンとデータの二つに分けて、対話エンジンは「データ」のインタプリタであると考えると、そのデータの部分を「コンテンツ」ととらえることができるわけです。
― 言語の文法や対話における基本構造は決まっているから、その構造をもとにした会話の生成エンジンと、シーンごとに用いられる言葉のデータセットを分けるということでしょうか?
土田:
おっしゃる通りです。
そしてこれを単に「データ」というのではなく「コンテンツ」としている意味合いは二つあります。一つは「使って楽しいもの」という意味合いです。コンテンツって、多くの場合エンターテイメントに使われるイメージが多いと思いますが、何かが普及していく時の要素の一つには、やっぱり使っていて「楽しい」とか「気持ちいい」とかがあると思っていまして、いつか「対話コンテンツクリエイター」みたいな人が出てきて、映像や音楽コンテンツを作るような感覚で、それを使用することを「楽しい」と感じる対話エージェントを作れるようにしたいという想いがあります。
もう一つの意味合いとしては、「流通していくもの」としてのコンテンツです。例えばゲームの世界ではUnityというとても有名なゲームプラットフォームがあって、今では多くのクリエイターがそこでゲームを制作し、他のクリエイターが作った素材などもその中で流通するといったエコシステムができています。対話エージェントも同じようにエンジンやプラットフォームを整備して、その上でコンテンツを流通させるマーケットプレイスまで展開すれば、コンテンツを作ってくれる人たちもどんどん増えていき、そういう人たちが、魅力的な対話エージェントを作ることで経済的な報酬も手にすることができる、みたいなのが理想ですね。
それで、そのような世界を作る第一歩として、当社では対話エンジンである「COTOBA Agent」をOSSとして公開したり、開発した対話エージェントを簡単に運用するための環境として「COTOBA Agentサービス」というプラットフォームサービスを提供しています。
― 研究や開発などでご苦労されてきたことはありますか?
土田:
最近はAI関連の研究もだいぶ変わってきている印象で、人材はもちろんですが、基盤技術に関しては大規模データとか大規模計算リソースの勝負になりつつあると感じています。
昔はどこも技術を囲い込んでいたと思いますが、特に深層学習については、IT巨人を中心に「大規模データと大規模計算リソースが強みになっていくから、技術なんてどんどんオープンにしよう」みたいな流れがある気がしていまして、ものすごくオープンになっていると思っています。もちろんオープンにしていないものもあるのだとは思いますが、かなりインパクトのある技術でもオープンソースにしていますし、すぐに論文になる印象です。このように、技術がオープンになっていても、データやリソースの問題で簡単には真似できないですし、オープンにすることで世界中の開発者によって技術が磨かれ、そういった技術がIT巨人のプラットフォーム上で利用されるといった関係もあると思いますし、技術をオープンにして失う強みよりも公開して得られる事業上のメリットの方が大きいということなのだと思います。
ただ、スタートアップは、そういうお金をどんどん投資する戦い方ができない典型ですから、同じような土俵で基盤となる技術を磨いていくというよりも、いかにオープン化された技術をビジネス課題に繋げるかっていうところがより重要になってきていると感じています。
その意味で対話システムって結構面白い部分がありまして、基本的に対話の大規模データなんて存在しないので簡単には作れないんです。
― 大規模データが存在しないんですか?
土田:
正確には、自分たちが作りたい対話システムに合った対話の大規模データが存在しないということです。
ある用途の対話エージェントを作ろうとする場合、まだ存在しないサービスの対話例ということになってしまいますし、どういう対話が良いかもそれほど自明ではありません。そのため、深層学習に必要な大規模データを収集したり人手で作りきるというのもかなり大変で、事実上誰も持っていないとみなせる訳です。ですから、誰がやるにしても、初期構築をして運用してデータを蓄積して改善してくみたいな地道なやり方になると思ってます。
文章生成の分野ではGPT-31といった巨大な言語モデルが出てきていて、時に人間と区別がつかない文章を生成してくれますが、特定の目的や用途に合わせた対話をよろしくやってくれるものではないと思っています。仮に対話システムの中でGPT-3を使ったとしても、なんとなく自然な対話を続けてくれるとは思いますが、それは対話エージェントのごく一部の側面で、特定の目的や用途のための対話にはコントロールが必要だと考えますし、そのためにはやっぱりサービサーが書くしかない部分があると思っています。
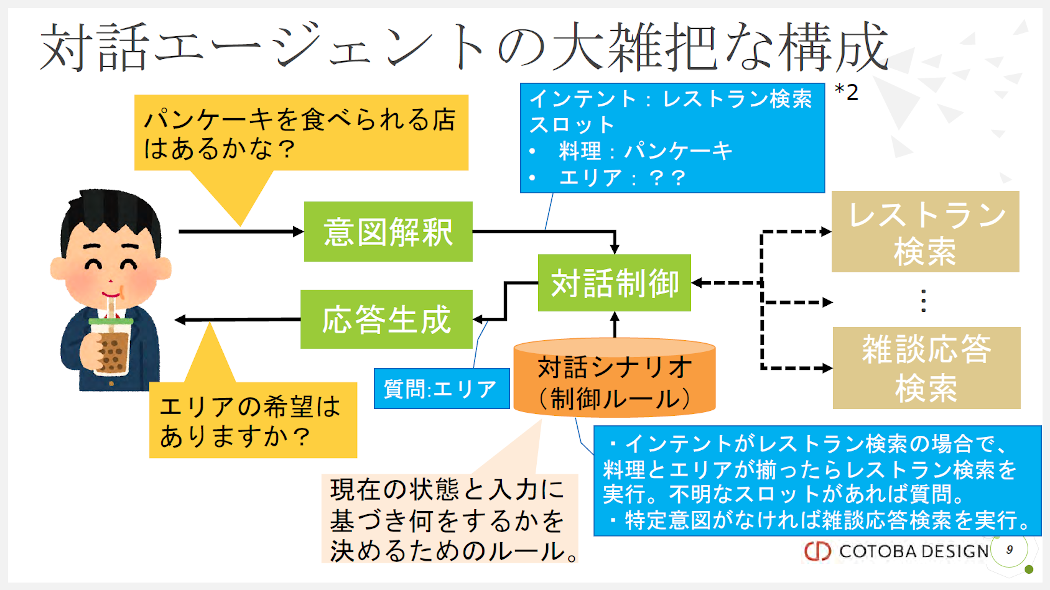
図2.対話エージェントの構成2
― ABCIを実際に使っていただいた感想はいかがですか?
松田 繁樹 (以下、松田):
やっぱり大量にGPUがあるので、いろんなパラメータを振って実験する時は非常に速いですよね。我われのようなスタートアップで沢山GPU買うなんてできませんが、ABCIを使えば普通に50個のGPUで並列でばっと実験を課して、一時間後にはもう全部そろってるみたいに使えますし。
土田:
確かにそうですよね。急遽必要になった追加実験とかでもすぐできてしまう。
松田:
そう、あっという間にできるんですよね。
― 学習やそのような実験で商用クラウドを使うことはあるんですか?
松田:
私はほとんどABCIだけですね。
土田:
研究開発はABCIですね。端的に言って値段が違いますし、商用クラウドは特定のユーザだけが占有できないように基本的には制限がかかっていて、現実にはたくさんのGPUを同時に使うことは結構難しいんですよ。
もちろん利用実績に応じて制限を緩和することはできますがABCIほど柔軟ではないですね。ABCIは背後の計算リソースが空いていれば、要求するだけでかなり同時に利用できるじゃないですか。
― では作ったモデルを最終的に外部の商用クラウドに持っていく時には、その実装はスムーズにできるのでしょうか?
土田:
そこはまあ、それができるように作っておくっていう逆の考え方ですね。
― ああ、実装を考慮した上で作るんですね。
土田:
もともとサービス自体は商用クラウドに実装することを前提にしているので、そういう作りをしておけば普通にできるという感じですね。
例えばですけど、Pythonの仮想環境でプロジェクト毎のPython環境みたいなものを作っておけるので、今のところは問題なくできてますね。
松田:
確かにABCIはPythonの環境とかTorchとか既にいろいろ入ってるので簡単に使えはするんですけれど、ものによって外部ライブラリのインストールがすごく難しいものもあって、そういう時にDockerで提供されてたりする環境があるので、それを使えればいいなと思うことはありますね。
土田:
ああ、確かに外部ライブラリのインストールに関しては、いろいろやると出てくるかもしれないですね。私の範囲だと偶然何とかなっただけかもしれないです。もし可能なら、今後「DockerユーザのためのSingularity講座」のようなセミナーを企画してもらえればもっと普及が進むのかもしれないですね。環境ライブラリも含んだコンテナが使えるって本来はものすごい魅力ですから。
― これからABCIの利用を検討している方に対して、何かアドバイスをいただければと思うんですが?
松田:
心情的には、あまり利用者が増えないで使いやすい方がいいかな。
土田:
同じこと考えてた(笑)。まあ、そんなこと言ってもしかたないんですけれど。
一つ言えることは、スタートアップで深層学習を行うのなら、とにかく使って損はないと思います。
サービス実装はできないですけど、研究開発とかモデル学習でGPUを使いたいときに、現時点でABCIより良いプラットフォームは無いと思っているので。大規模実験が必要とか、深層学習のモデル開発が競争力の源泉とかそういう場合は別ですが、そうでないスタートアップであれば、最小購入の1000ポイント(20万円)でも十分に使えると思います。
― ありがとうございます。最後に今後の展開を教えて下さい。
土田:
そうですね、長期的な意味では先ほどお話した通りですが、直近の話でいうと、今提供している対話エージェントのエンジンやプラットフォームを、私たち自身が使いながら、対話ソリューション・対話エージェントの価値というものをより多くの方に提示しつつ、その次のマーケットプレイスの方に行くような準備を進めていければと考えています。
株式会社 コトバデザイン