2020年からの新型コロナウィルス(Covid-19)の流行により、私たちはワクチンや新薬開発のニュースをより身近なものとして捉えるようになりました。わが国の研究機関で創薬分野の中核にある国立研究開発法人 医薬基盤・健康・栄養研究所様では、創薬におけるAI活用を目的に、AI健康・医薬研究センターを立上げて新薬の開発を加速化するための基盤研究に尽力されています。今回は同センターで、国の指定難病に対してAIを用いた新薬開発の手法を研究する事業のリーダーを務める夏目様にお話を伺いました。

国立研究開発法人 医薬基盤・健康・栄養研究所 AI健康・医薬研究センター バイオインフォマティクスプロジェクト
プロジェクトリーダー 夏目 やよい 様
― それでは、夏目さんのいらっしゃる研究所と事業についての簡単なご紹介からお願いします。
夏目 やよい(以下、夏目):
はい、私が働いております医薬基盤・健康・栄養研究所ってすごく長い名前の組織名なんですけれども、元々は医薬基盤研究所という研究所と、国立健康・栄養研究所という2つの国立研究所が合併してできたものです。この医薬基盤研究所が、薬を作るために有益な基盤研究、基盤技術の開発といったことを行っていまして、国立健康・栄養研究所のほうが、人の健康ですとか、栄養に関することについての研究を幅広く行っている研究所です。私は前者の医薬基盤研究所の中にあるAI健康・医薬研究センターというところにおり、「新薬創出を加速する人工知能の開発」をテーマとした事業を担当しています。
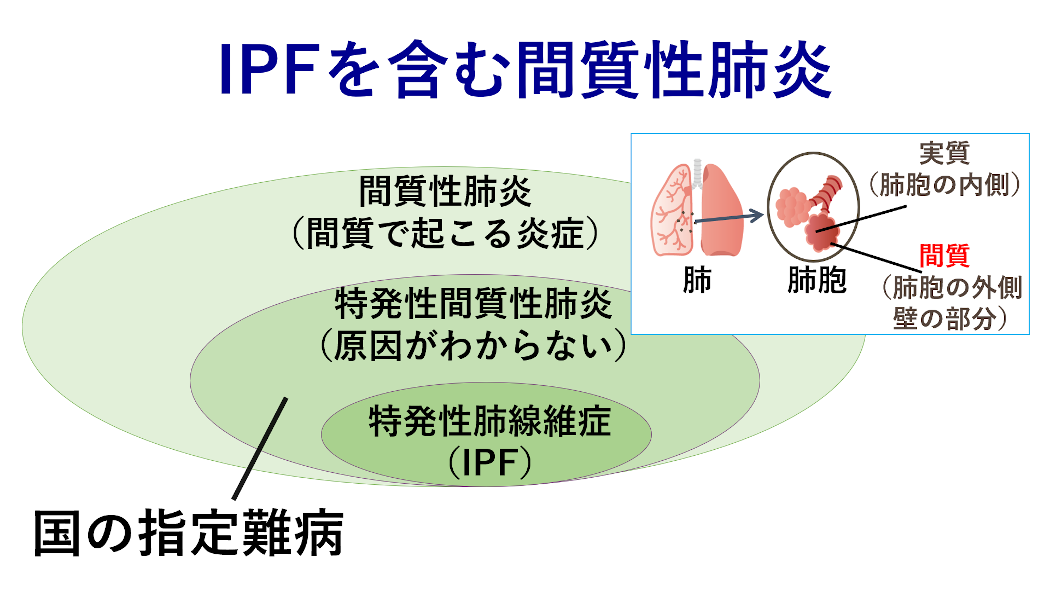
そもそも創薬は、莫大な資金と、10年以上にも及ぶ長い年月が必要であるにも関わらず、決して成功率が高いとは言えない、かなりハイリスクな産業です。これをどうにかして効率化したいという需要がありまして、私たちは新薬創出を人工知能(AI)の力を借りて加速させるための基盤となる研究を行っております。そして、薬を作る上でのプロセスもいろいろありますけれども、私たちはその中でも「創薬標的」と呼ばれる、要はこの薬はこのタンパク質1に影響を与えてそれによって病気を治す、そういう効き所になるのですが、その創薬標的をAIの力を借りて探索するような技術開発を行っております。
― なるほど。「標的」というものの多くは、人体のさまざまな器官や筋肉を構成するタンパク質になるということですね。でも、そもそも、そのタンパク質の種類とか、構造・機能に関してはどこまで解明されているのでしょうか?
夏目:
そうですね、人のタンパク質は10万種類ほどになるのですが、だいたい網羅的に解析が済んでいて、こういったアミノ酸配列のタンパク質があるということはわかっているんです。ただ、その機能などがどのくらい研究されているかというのは、タンパク質によってかなりムラがありますね。あるタンパク質については、このようなシチュエーションでこんなふうに働く、この病気と関連している、というようにすごく知識が溜まっているけれど、別のタンパク質はどんなものなのかあまり知られていない、といった具合です。
例えば、生物学の研究において「癌の人だとこの遺伝子に変異が入っている、その変異によってこのタンパク質がおかしくなるから癌になるのだ」という報告が出れば、じゃあそのタンパク質についてもっと知見を深めようということで、一種のブームのような形でそのタンパク質の研究が進みます。ただ、他のタンパク質も、もしかしたら同じ病気に重要かもしれないのですけれども、それが重要だという報告が出てこないと、同じようには研究が進まないというところで差が出てきてしまいますね。
― いまお話のあった創薬標的となるタンパク質の選択や評価というのは、AIを導入する前はどのように行われていたんですか?
夏目:
創薬標的を探すというときには、通常、薬を開発したい病気について研究を行って、純粋な生物学の領域で、あるタンパク質または何かしらの体の中にある分子で「これがキー(創薬標的)になりそうだ」と当りをつけます。次に、そのタンパク質なり何なり生体分子の機能をコントロールできるような化合物を作ります。そして、その化合物に毒性があると薬としては使えないので、安全性を確認するなどきちんと薬の候補としてブラッシュアップして、臨床試験に進んで行くのです。けれども、AIを導入する前は、その病気について、分子レベルで理解が進んでいないと「標的としてこれが使えるんじゃないか」という当りをつけること自体がそもそも難しいというところがありました。
ですので、そういう創薬標的を、典型的な生物学・医学の研究で見つけるのが難しい状況にあるのであれば、生物学的な知識が蓄積してなくても、データを集めれば創薬標的が見つかるという状況にすればいいですよね、ということで始まったのが私たちの事業です。そこで、私たちは国の指定難病として位置づけられている病気で「特発性肺線維症(IPF)2」という病気に着目しました。IPFの場合にも、その病気についての分子レベルでの理解が十分に進んでいなかったので、IPFを治すためにはどういう薬をつくれば良いのかもなかなか研究が進んでおらず、いま市場に出ている薬が2種類しかないというような状態だったんです。
― 開発された手法というのは一種のシミュレーションのようなものなのでしょうか?
夏目:
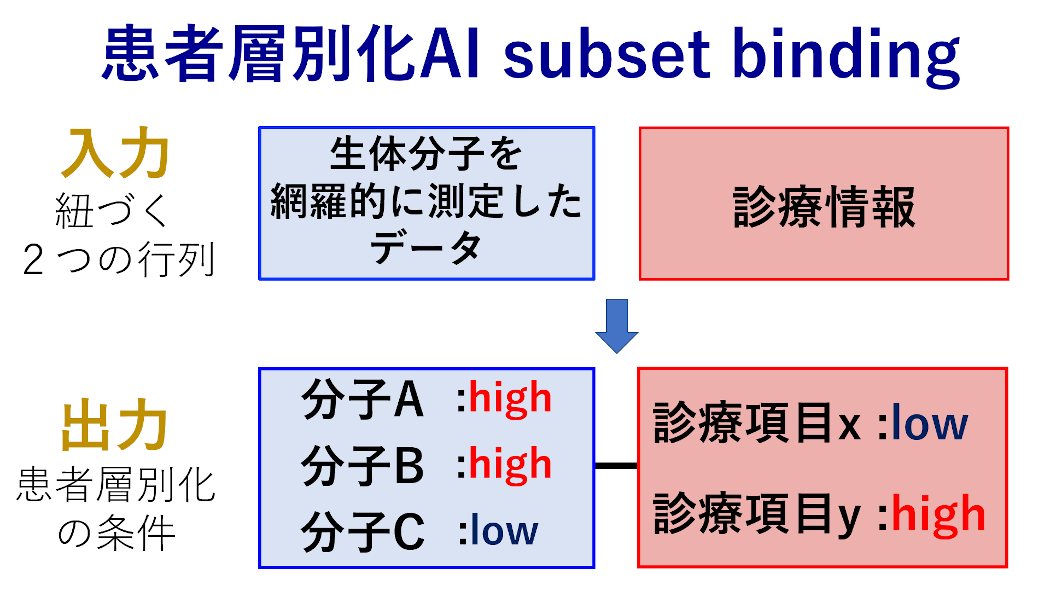
シミュレーションというよりも、データマイニングやパターン認識ですね。実際に私たちが行ったのは、患者さんからタンパク質などを網羅的に測定したデータと診療情報の2つを収集しまして、そこから診療情報レベルで、こんな特徴のある患者さんはタンパク質ではこれが多かったり少なかったりしますよという傾向を、データ駆動的に出力させるようなアルゴリズムを作ったんです。そうすると、IPFの特徴を満たすような患者さんで、変動しているタンパク質というのがわかるので、そこから創薬標的を探そうというアプローチにしました。
― なるほど、よくわかりました。研究にあたってAIの計算環境面などで苦労されませんでしたか?
夏目:
そうですね、どちらかと言うとこの事業では、データ解析よりもデータ収集する方が苦労したので、解析環境という意味合いではそこまで困らなかった…、困らなかったと言いますか、あの、ABCIのおかげなんです(笑)。それまでは研究所の中にあるサーバーで解析を行っておりまして、ただそれだとちょっとスペック不足で、検出したかった出力結果を得るところには至らなかったので、メモリを食わないようにアルゴリズムを修正するか、あるいは、スペックの高いマシンを使うかという2択が必要だったんです。しかし、やはりこういう事業ですと、成果を早く求められるというのもありますし、アルゴリズムを開発して論文書けば終了というものではなく、そこから実際に創薬標的を見つけるところまで行かないといけません。結局、スペックの高いマシンを使う方が早いし簡単ですので、ABCIを見つけて使うということになりまして、それで無事解決しました。
― ありがとうございます。でも医薬の分野だと、プライバシーやセキュリティ面で厳しい部分も出てくるかと思うんですが、そこはどのようにクリアされたんですか?
夏目:
解析するデータは仮名加工をするなどして、個人名や生年月日など創薬標的探索に関係のない個人情報は含まない形にする対処を行なっています。また、IRB3と言って人のデータを使う研究に関する審査があるのですけれど、その申請で、スパコンを使ったデータ解析も含むというふうに書いてあれば、それで許可が下りれば使うことはできるんです。幸いABCIの場合には、情報セキュリティのガイドラインなどもきちんと公開されておりましたので、周囲の理解は得やすかったと考えております。
― 現在は研究全体のなかで何合目くらいのところにいるのでしょうか?
夏目:
事業全体のゴールとしては、7,8合目というところでしょうか。データ解析をして、創薬標的の候補になるものは見つかってきたので、現在はそれを実際の生物学実験で、いろいろ検証をしているところです。そして、開発したアルゴリズムについても、一応使えることは使えるのですが、もっとブラッシュアップしたいであるとか、まだいくつか課題も残っている状態ですのでだいたいそのくらいかなというふうに思います。
― 今後は他の病気についても応用できそうですね。
夏目:
そうですね、私たちの事業としては、診療情報だとか分子レベルの情報を集めれば、データ駆動的に創薬標的を見つけることができるんだ、というPoCをまずしたかったというところがあります。このIPFについては実際に標的候補を提示するところまでできたので、これと同じワークフローで他の疾患についても同様にデータを集めて解析すれば、創薬標的の候補を見つけることはできると思いますし、今後はそのように展開していければと考えております。
長期的なビジョンとしては、私は元々の専門が生物学なのですけれども、生物学の研究の新たなアプローチとして、この機械学習のような新しい技術を導入することで、今までは全然わからなかったことが、どんどんわかってきて、「生物ってどうしてこんなに精密に体がコントロールされているんだろう」ということを、もっと理解できるようになるといいなと考えております。そして、そのような理解が深まることが、結局は次の創薬につながったり、より健康的な生活につながったりするのだと思います。
― 実際にABCIをご利用いただいての感想など伺えますか?
夏目:
そうですね、先ほど少しお話をした「アルゴリズムを改良するか、マシンのスペックを上げるか」というところで、マシンのスペックを上げるためにスパコンの利用を急遽検討することになったのですが、他のスパコンですと利用申請の時期が決まっていることが多いです。私たちの場合、アルゴリズムの開発当初は自前のサーバーでデータ解析できると思っていましたので、スパコンの利用というものが検討されていなかったんですね。なので、そうしたスパコンの公募の時期を待っていると、時間だけが過ぎてしまうという状況だったのですけれど、ABCIですと申請をしてすぐに使えるし、あとはポイント制ということもあり、ちょっと様子見で使う場合も手を出しやすかったというところがあります。
また、もともとはスパコン利用を考えていなかったということもあって、探索アルゴリズムもごく普通のサーバーを使うことを前提にpythonで書いていたんですけれども、それもまったく問題なく動きましたので、いまは創薬標的探索の解析ではABCIをメインで使わせていただいております。
― これからABCIを利用検討いただく方に向けて、一言アドバイスなどあればお願いします。
夏目:
そうですね、やっぱりこういうデータ解析を伴う研究は、今後も扱うデータのサイズがどんどん増えていくことが確実で、必要なマシンのスペックもどんどん上がると思うんです。それを個々の研究室などで、購入管理するというのは相当な負担になってしまうのですけれど、ABCIのようなリソースを使うことで、大きなデータ解析を伴う研究もすごくハードルは下がるかなというふうに思うんです。なので、こういった外部のクラウド環境を使って、マシンの管理などに割く負担を減らすということも考えながら、効率よく研究を進めるというのは、今後は必要な戦略になるんじゃないかなと思います。
あと、私がすごくありがたいなと思っているのがSlackなんですよね。あの、ABCIユーザコミュニティのSlackグループがあって、いろいろ情報発信して下さっていて、こちらで紹介されたセミナーに参加していろいろ勉強できたり、そういった直接マシンとは関係ないところでのサポートというのも、すごく勉強になってありがたいと思っております。もし良ければ、今後もこのABCIユーザーのSlackのグループでは、なにかABCIを使うことに絡んだ、例えば「実はABCIでこんなこともできる」みたいな、ちょっとしたコツやテクニックですとか、そういった情報を発信いただけるとより良いのかなと思いました。
国立研究開発法人 医薬基盤・健康・栄養研究所 https://www.nibn.go.jp/