国立研究開発法人 日本原子力研究開発機構(JAEA)様は、日本で唯一の原子力に関する総合的研究開発機関です。「ABCI利用者インタビュー」今回は同機構)高度計算機技術開発室で、都市レベルの風の流体解析の研究に挑まれている小野寺様と、室長の井戸村様にお話を伺いました。

国立研究開発法人 日本原子力開発研究機構
システム計算科学センター高度計算機技術開発室長 井戸村 泰宏 様(左)
システム計算科学センター高度計算機技術開発室 小野寺 直幸 様(右)
ー どのような研究に、ABCIを使っているのでしょうか?
小野寺 直幸(以下、小野寺): リアルタイムで風を解析することを目指しています。この研究は日本原子力研究開発機構(JAEA)では、核セキュリティに役立つ研究と位置付けられています。
ー 核セキュリティとはどんなことですか?
小野寺:
放射性物質が環境に放出される状況は、事故やテロなどが考えられますが、いまニーズが高いのは原子力発電所の廃炉作業です。作業が進むと、いろいろな設備が取り払われていきます。その中で放射性物質の環境放出がないように、工程を調整しながら作業していきますが、万一放出された場合にどのくらい環境への影響があるか、放射性物質の拡散を事前に評価する必要があります。
JAEAとしての目的は放射性物質の拡散評価ですが、シミュレーション研究としても科学的に興味深いテーマです。これは2mの解像度で、東京都心のビル1個1個をとらえた風のシミュレーションです(図1)。現在はリアルタイム、すなわち、実際の時間と同じ計算時間での解析を目指していますが、将来的には深層学習を利用して、その10倍、100倍といった速さで大規模な予測を行い、何か災害が起きたときに放射性物質の拡散を予想したいと考えています。
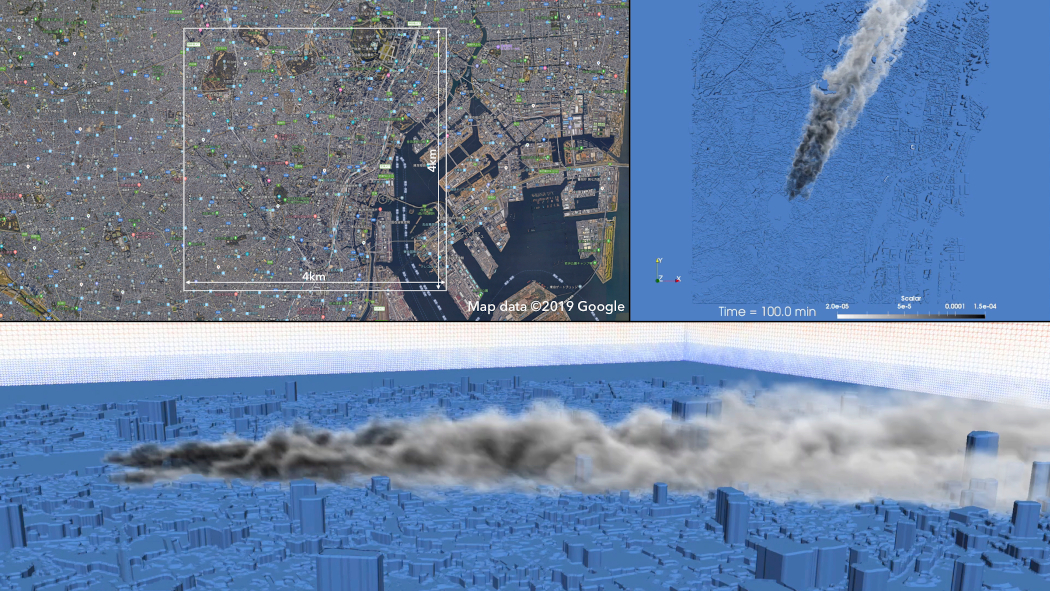
現在は深層学習というよりは、大型計算機を使った数値流体解析を行っている段階です。主に用いている計算資源は東京工業大学のTSUBAMEとABCIで、どちらもGPUを搭載したスーパーコンピューターですので、GPUに適した計算手法を作っています。気象予報の格子は500m、1kmといったスケールなので、それを2m程度の解像度の細かい格子とつなぐような手法も同時に開発しています。
TSUBAMEとABCIではGPUの世代が違いますし、ネットワークの機構も違います。それらを比較して異なる世代のGPU環境の処理特性を明らかにすることを目指した性能測定も行っています。このような処理特性に基づいて、将来的により高性能のシステムができたときに、より詳細な計算がより少ないGPUでできる、あるいは、より短時間でできることを目指した計算手法の開発にも取り組んでいます。

ー コンピューターの性能をより引き出すには、どのような手法があるのでしょうか?
井戸村 泰宏(以下、井戸村):
スケーリング(拡張性)の性能測定にはウィークスケーリングと、ストロングスケーリングがあります。ウィークスケーリングでは1つのGPUに決まった大きさの問題を解かせるので、GPUの数を増やしていくと問題の大きさは大きくなりますが、1つのGPUが解く計算量は変わらないので処理時間が短くなることはありません。
ストロングスケーリングでは、逆に問題全体の大きさを決めて、GPUの数を増やしていきます。すると1つのGPUあたりの計算量が減っていくので、処理時間が減っていきます。ウィークスケーリングはどれだけ大きな問題を解くことができるか、ストロングスケーリングはどれだけ計算を加速できるか、という違いです。
小野寺:
ウィークスケーリングとストロングスケーリングの両方で、TSUBAMEとABCIを使って性能を測定しています。ウィークスケーリングでは1GPUあたりの計算領域を320m四方で固定して、GPUの数に比例して全体の計算領域を拡大します。196GPUの大規模計算では4.5km四方の計算領域に対して、ABCIではTSUBAMEの1.57倍の高速計算ができました。ストロングスケーリングでは計算領域を2km四方で固定して、GPUを増やしていきます。そうすると1つのGPUが受け持つメモリーの体積に対して、通信の表面積は大きくなっていくので…
ー メモリーの体積と通信の表面積って、どういうことですか?
小野寺:
3次元シミュレーションなので、計算量は解析する空間の体積で決まります。その計算領域を各GPUに割り当てると、隣の領域と通信が必要になるので、通信量は表面積になるのです。
ー なるほど。シミュレーションの領域を分割してGPUに計算させると、隣接した領域を計算しているGPUとの間で、計算結果を交換しなければならないから、分割するほどGPU間の通信量が増えていくのですね。
小野寺:
ストロングスケーリングの場合、GPUの演算性能だけでなく通信性能もすごく重要になってきますので、通信の削減手法を用いることでストロングスケーリングに強いアルゴリズムを作りました。1mの計算解像度でリアルタイム計算をするのにTSUBAMEでは400GPUが必要だったのですが、この手法を用いることで100GPUでできるようになりました。ABCIだと、135GPUだったのが60GPUでできるようになりました。
ー TSUBAMEとABCIの性能差で比較すると、もともとTSUBAMEでは400GPU必要なのがABCIでは135GPUで同じ速度になり、アルゴリズム改善後は100GPUから60GPUということになりますね。
小野寺:
ABCIはGPUの世代が変わり、こちらが目的としているリアルタイム計算がよりコンパクトなシステムで実現できるようになりました。
井戸村:
京(理化学研究所のスーパーコンピューター)と比べて、ABCIのプロセッサーあたりの処理速度は60倍になっています。しかしプロセッサー間の通信速度は京が毎秒20GB、ABCIは毎秒25GBで、あまり違いがありません。だから、こういう大規模計算では演算も大変なのですが、演算が速すぎて通信が追い付いていないんです。それを解決するために通信を削減するアルゴリズムを組んで性能を向上しました。一般に、大規模なシミュレーションをやっている人が一番苦労するところだと思います。

小野寺:
先ほど見てもらったのは、4km四方の東京の地形データに風の情報を加えて、2m解像度で汚染物質の拡散をシミュレーションしたものです。こういうシミュレーションをリアルタイムぐらいでできるようになっています。次のターゲットとしては、このシミュレーション結果を使うことでリアルタイムの10倍、100倍と加速して、予報するようなことをABCI上で一貫して行いたいと考えています。 建物ひとつひとつの細かい流れは、深層学習で予測できるという論文も結構あります。日々の気象データをリアルタイムでシミュレーションしていくと、膨大なビッグデータを生み出すことができますから。
ー リアルタイムでは予報に使えないから、建物の周りの風は厳密に計算しなくてもだいたいこうなるはずだ、というモデルを作ってしまおうと。
小野寺:
そうですね。いろんな風の流れといろんな建物形状のパターンができたら、違う土地の建物データでもリアルタイム計算をせず、学習した結果から予報できるんじゃないか、あるいは、いろんな都市でも即時予報ができるんじゃないかと見込んでいます。
ー 今のお話を伺うと、スーパーコンピューターの使い方として全く違う2つの使い方を組み合わせているわけですよね。厳密なシミュレーションと、それを基にしたビッグデータの深層学習。 ビッグデータと言うと、現実のデータを収集して解析し学習するイメージだったのですが、シミュレーション結果もビッグデータになり得るのですね。
井戸村:
現実のデータを膨大に用意するのは大変ですが、シミュレーションならいくらでもデータを作れます。しかも実験だと十分に広範囲なデータを取れない場合もありますが、シミュレーションは自在に風速を設定して、実験で想定される範囲に比べて十分に広い状況に対して機械学習を可能とするようなデータベースを作れるのが一番大きな特徴かなと思います。
ー なるほど、実データだと機械学習に使えるようなきれいなデータセットにするのに手間がかかると聞きますが、シミュレーションならきれいなデータを作るようにすればよいですね。
小野寺:
そうです。同じ研究者が同じ計算機でやっていますから、データのどれがどういう意味を持つかということもはっきりわかっていますので、そういう意味では一貫しているのは大きいのかなと思います。
ー 同じ計算機でシミュレーションと深層学習をしていることにも意味があるのですか?
小野寺:
大規模なシミュレーションをすると、数百TBのデータも簡単に作ることができますが、それを計算機間で移動させることってできないんです。あまりにもデータ量が大きすぎて、通信で送るのは現実的ではありません。そうなると、大規模シミュレーションと深層学習をする計算機はストレージを共有している必要があります。それを一貫してできるシステムはありがたいですね。

ー ABCIや他のスーパーコンピューターの中から、使用するシステムを選ぶ際にはどんな理由があるのですか?
小野寺:
ABCIを使うのは明確な理由があります。いま、一般利用で2000GPUまで同時使用できるシステムは、日本にはほかにありません。世界的にもほとんどないですね。こういう最先端のシミュレーションを開発する環境として、ABCIは欠かせません。
井戸村:
JAEAではエクサスケールコンピューター(100京FLOPS規模のスーパーコンピューター)という、次世代のシミュレーション環境を視野に入れたシミュレーション技術の開発を行っていますが、そういうところを見据えるとやはり現在使える最大規模のシステムを使いたい。
ー 実際に役に立つものを作り出す研究だけでなく、まずコンピューターを使いこなすことそのものも研究対象になるのですね。
井戸村:
現時点で使われている実用的なシミュレーションに、エクサスケールコンピューティングが必要なくても、そういう技術を開発することで次世代のシミュレーションに役立っていきます。
例えば、京コンピューターのプロジェクトが始まった頃には、産業界ではパソコンレベルの簡易的な解析しかやっていませんでしたが、京コンピューターで様々な産業応用アプリケーションが使えるようになったことで、産業界もスーパーコンピューターを使うようになってきています。
ー GPUを2000個同時に使えるABCIも、その能力を発揮できるような使い方をできる人がまだ産業界に少ないということですね。そのあたりで日本と外国の差はあるのでしょうか?
井戸村:
GPUを利用するスーパーコンピューティングに関しては、かなりアメリカが進んでいます。日本では、CPUを使っている京コンピューターに力を入れてきたので、CPU主体の利用が進んでいます。アメリカでは前の世代からGPUスーパーコンピューターを使ってきたので、GPUの方がメジャーになりつつある感じです。アメリカ発のフリーウェアやオープンソースのシミュレーションなどは、かなりGPU対応が進んできています。
ー 研究界から産業界へ、もっとスーパーコンピューティングを応用していくのはどのようなルートがあるのですか?
小野寺:
いろいろあると思いますが、例えば、産業応用の共同研究で企業と連携してアプリケーションを共同で開発、利用するような取り組みがあります。別の方法としては、我々が開発したプログラムをオープンソースで提供し、それを使っていただくといった取り組みも積極的に進めています。
ー ABCIは深層学習やAIを主眼に置いて作られたシステムですが、それ専用ではなく同じコンピューターの中で、深層学習の元となるシミュレーションもできることが重要だというお話が、大変勉強になりました。
聞き手 大貫 剛(ライター)
国立研究開発法人 日本原子力研究開発機構 https://www.jaea.go.jp/